- Published on
高精度 OCR 图片文字 AI 消除
- Authors

- Name
- Sean
- @him50653330
背景
我们需要一个工具将图片中的文字进行去除,传统的手段对于文字去除的效果并不好,尤其是遇到复杂场景,往往需要复杂的图像处理手段来进行处理,而且可能还需要“人工”智能来帮忙。
我们尝试了 ffmpeg 的方式对文字进行去除,但是只有文字在纯色或者简单背景下 ffmpeg 的处理才能说的过去。
随后,我们在 Github 上找到了 IOPaint(原 lama-cleaner) 这个项目,他能借助 AI 模型的能力帮助我们实现良好的图片处理效果。
IOPaint(lama-cleaner)
IOPaint is a Image inpainting tool powered by SOTA AI Model. Remove any unwanted object, defect, people from your pictures or erase and replace(powered by stable diffusion) any thing on your pictures.
项目地址 | 官方网站
IOPaint 提供了一系列的图像处理 AI 能力,包括涂抹、inpaint、outpainting 等等,非常好用,而且成本不高。可以选择使用不同的模型。
Version 1
第一个版本很简单,我们使用 PaddleOCR 识别出了图片中的文字位置,然后将这个位置生成成一个模版给到 IOPaint 的 API。
from paddleocr import PaddleOCR
def ocr(image):
# 使用 PaddleOCR 识别图片中的文字
result = PaddleOCR(use_angle_cls=True, lang="ch", show_log=False).ocr(image, cls=True)[0]
return result
def inpainting(origin_image_bytes, words, width, height):
# 生成 IOPaint 的模版并调用 IOPaint 的 API
# origin_image_bytes: 原始图片的字节流
# words: 识别出的文字位置
# width: 图片宽度
# height: 图片高度
mask = Image.new("RGB", (width, height), "black")
draw = ImageDraw.Draw(mask)
for word in words:
draw.rectangle(word["inpainting_position"], fill="white")
with io.BytesIO() as output:
mask.save(output, format='PNG') # 保存为PNG格式的字节流
mask_data = output.getvalue()
r = requests.post(inpaint_api_url,
files={
"image": bytearray(origin_image_bytes),
"mask": mask_data
},
data={
"ldmSteps": 25,
"ldmSampler": "plms",
"zitsWireframe": True,
"hdStrategy": "Crop",
"hdStrategyCropMargin": 196,
"hdStrategyCropTrigerSize": 800,
"hdStrategyResizeLimit": 2048,
"croperX": 256,
"croperY": 256,
"croperHeight": 512,
"croperWidth": 512,
"useCroper": False,
"sdMaskBlur": 5,
"sdStrength": 0.75,
"sdSteps": 50,
"sdGuidanceScale": 7.5,
"sdSampler": "uni_pc",
"sdSeed": -1,
"sdMatchHistograms": False,
"sdScale": 1,
"cv2Radius": 5,
"cv2Flag": "INPAINT_NS",
"paintByExampleSteps": 50,
"paintByExampleGuidanceScale": 7.5,
"paintByExampleSeed": -1,
"paintByExampleMaskBlur": 5,
"paintByExampleMatchHistograms": False,
"p2pSteps": 50,
"p2pImageGuidanceScale": 1.5,
"p2pGuidanceScale": 7.5,
"controlnet_conditioning_scale": 0.4,
"controlnet_method": "control_v11p_sd15_canny",
"prompt": "",
"negativePrompt": "",
"sizeLimit": max(width, height)
}
)
return r.content
中间的这些参数你可以在 IOPaint 的 Web 应用调用的 API 中获取,你可以自己设置不同的参数获取不同的效果。
IOPaint 的效果非常好,我们 70% 的图片都能达到我们的预期效果,但是还有 30% 的图片效果不好,我们需要进一步优化。



可以看到第三张效果图中,文字的边缘有一些残留,部分文字没有被涂抹干净,主要的原因是因为 PaddleOCR 给出的文字位置有可能紧贴着文字,也有可能正好卡在文字后面的背景框上(其他图片会有此类问题)
图中蓝色的框是 OCR 识别的区域,红色的框是我们最初版本重新计算的区域。
我们统计了第一批测试的 100 多张图片的效果,总结了会碰到的一些具体情况:
- 字号偏大的斜体文字,会出现涂抹不全的问题
- 有颜色 border 的文字
- 有复杂的、不规律的背景色块,容易出现涂坏的效果
- 文字如果出现在人脸上,IOPaint 也无法正确处理
- 小字号文字带有比较紧贴的背景边框或颜色背景时,容易涂坏
- 小字号的纵向文字
- 带括号的文字
- 文字出现在物体上的情况
- 文字出现在物体边上的情况
同时我们邀请了 5 位同学对某一类目下的图片进行结果评估标准,用来初步建立我们的效果评估体系。
问题分析
- 识别出来的边框过于紧贴文字,会导致涂抹的时候出现问题
- 符号会超出识别出来的边框,字号越大越明显
- 小字号的文字容易出现识别出来的边框范围过大,会导致涂抹时触及到背景的元素
- 人脸上 IOPaint 无法正确处理,没有合适解法
- 【8】、【9】问题的原因是因为算法问题导致了涂抹的区域横向过大,导致了涂抹到了物体上
关于为什么字号越大边框会越有问题,这里可以了解一下文字渲染的原理:LearnOpenGL - 文字渲染
解决方案
首先,我们需要扩大 OCR 出来的文字边框,避免边框贴住文字的情况,但是扩大多少,是一个问题。
那么首先我们使用固定系数来扩大涂抹的区域,包括 IOPaint 的 Demo 也是这么做的,显然这样的效果并不会好。
那我们应该怎么来扩大这个区域呢?
首页我们需要判断边框是否完全框住了我们的文字内容,如果没有我们应该让边框向外扩展至完全框住;
然后,我们希望区域越大扩大的越少,区域越小扩大的越多,同时有一个最大的限制避免区域过大;
OK,看下代码怎么实现
def auto_spread(canny_image, start, f, t, axis, word, threshold, move=-1):
# 自动扩展边框
# canny_image: 二值化原图
# start: 开始位置
# f: 开始位置偏移量
# t: 结束位置偏移量
# axis: x or y
# word: 识别出来的文字位置
# threshold: 扩展的阈值
# move: 扩展的方向
width, height = canny_image.size
init_start = start
while True:
if start - threshold == 0 or start <= 0 or start >= (width if axis == "x" else height):
return start
colors = []
for i in range(0, round((t - f) / 2)):
colors.append(canny_image.getpixel(make_spread_point(axis, start, f + i)))
colors.append(canny_image.getpixel(make_spread_point(axis, start, t - i)))
black_count = len(list(filter(lambda x: x == 255, colors)))
if not 255 in colors:
return start
start = start + move
# 计算 X 轴的最大扩展值
# max_x - x 计算边框的宽度
# x_offset_min 为最小的扩展值, 默认是 3 个像素
# x_offset_log 为扩展值的对数底,默认是 0.5
# width 为图片的宽度
# 使用识别宽度 / 图片宽度来定义识别区域的“大、小”,使用对数函数来控制扩展值的变化,越大的比例,扩展值越小
x_offset = round((max_x - x) * max(x_offset_min, int(math.log(((max_x - x) / width), x_offset_log))) / 10 / 2)
# 自动扩展边框,保证边框完全框住文字,x 轴左右两边分开计算
new_x = auto_spread(canny_image, x, y, max_y, "x", word["word"], x - x_offset, -1)
new_max_x = auto_spread(canny_image, max_x, y, max_y, "x", word["word"], max_x + x_offset, 1)
函数曲线如图所示:
横轴为识别宽度 / 图片宽度
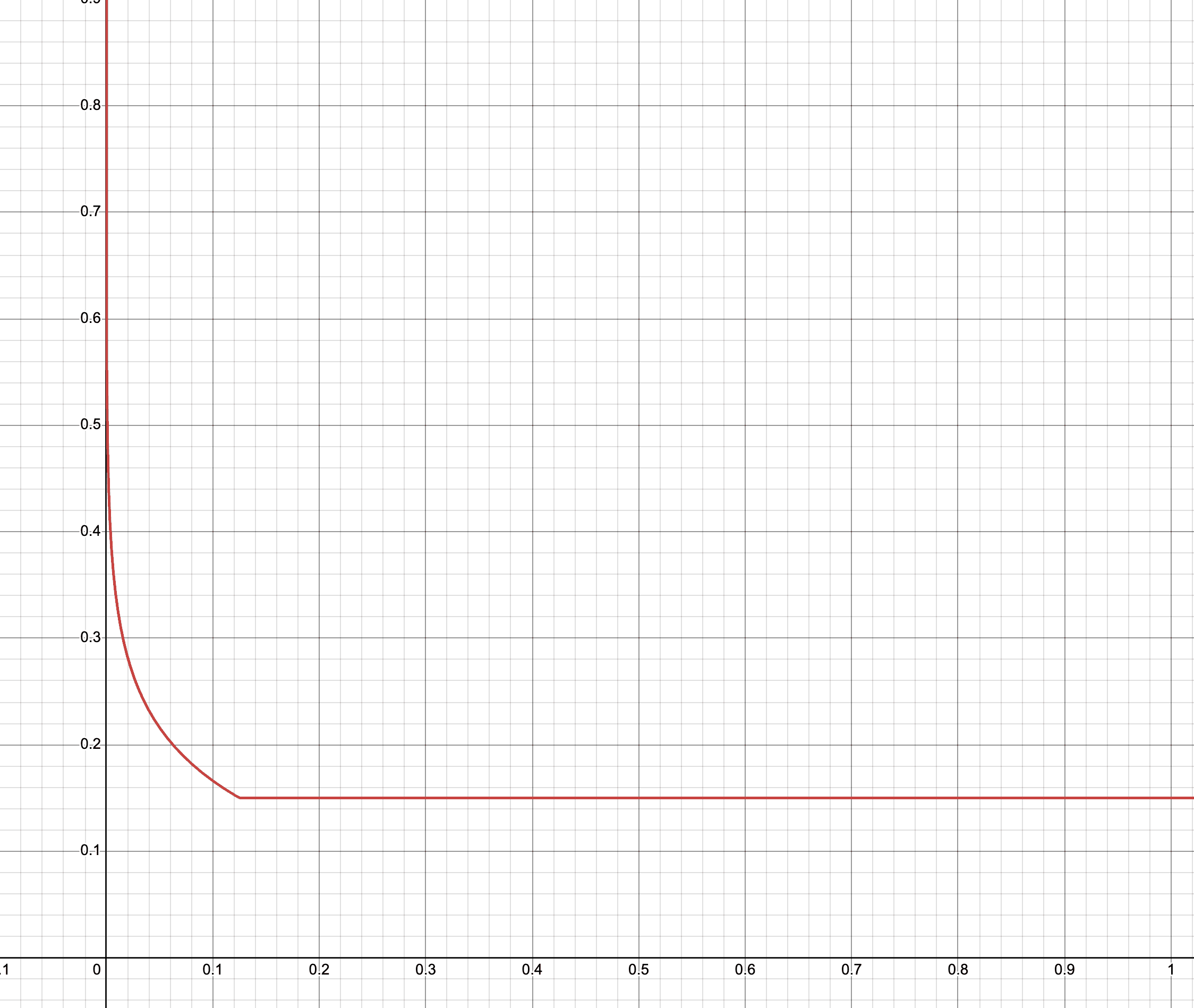
# 计算 X 轴扩大的像素与识别宽度的比例
x_increase_rate = (x - new_x) / (max_x - x)
max_x_increase_rate = (new_max_x - max_x) / (max_x - x)
# 计算最终的扩大值
# fs_x_default: 当扩散值小于等于最小扩散阈值时,使用此默认值,默认是3像素
# fs_x_default_threhold: 最小扩散阈值, 默认0
# fs_x_direct_mutiple: 当扩散比例大于最大扩散比例阈值时,使用此倍数,默认是 0.5
# fs_x_rate_threhold: 最大扩散比例阈值,默认值 0.03
# fs_x_log: 计算对数的底,默认是 0.5
# fs_x_max_threhold: 最大扩散值比例阈值,默认是 3
r_x = new_x - (fs_x_default if x - new_x <= fs_x_default_threhold else (x - new_x) * (
fs_x_direct_mutiple if x_increase_rate > fs_x_rate_threhold else math.log(x_increase_rate, fs_x_log) - fs_x_max_threhold))
r_max_x = new_max_x + (fs_mx_default if new_max_x - max_x <= fs_mx_default_threhold else (new_max_x - max_x) * (
fs_mx_direct_mutiple if max_x_increase_rate > fs_mx_rate_threhold else math.log(max_x_increase_rate, fs_mx_log) - fs_mx_max_threhold))
最大扩散值比例曲线所示:
横轴为扩散比例
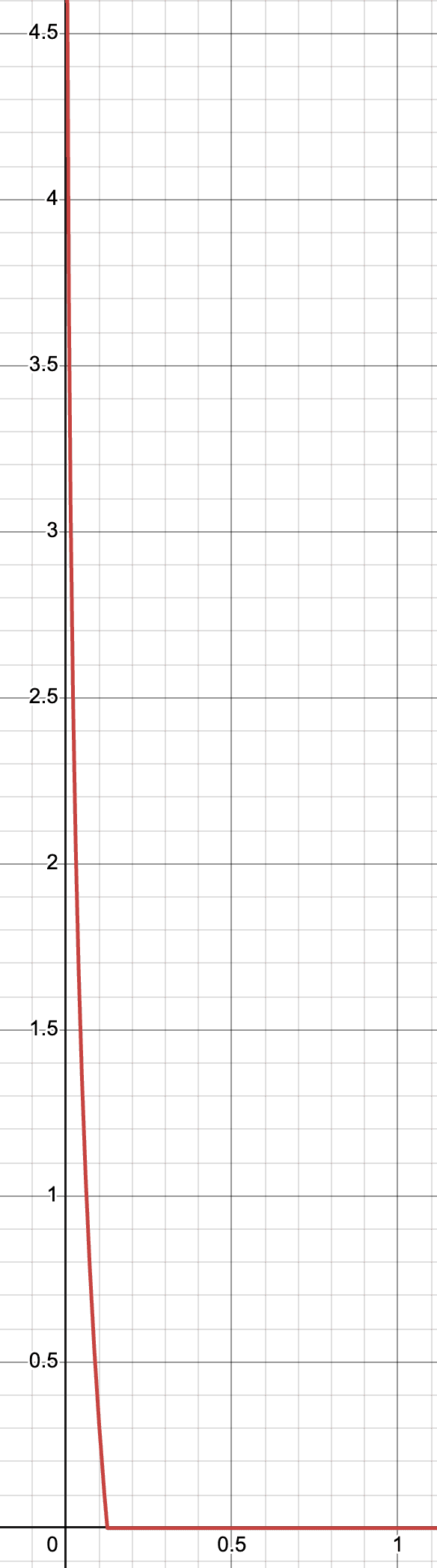
Y 轴同理,共记 29 个参数,这里不再赘述。
下面是最后的效果

建立测试集
有了这 29 个参数,我们可以对效果作出更加细微的调整,但是怎么看调整的效果呢?怎么确保这次的改动对之前的效果产生影响呢?不可能每次都把所有图片都运行一遍。
我们需要一个测试工具,能够对测试的改动进行快速高效的评估。
所以我们针对生产环境中出现问题的错误图片建立了“错题集”。随着生产环境的不断更新,这个错题集也会变得越来越完善。
我们使用 jupyter notebook 建立了一个测试环境,每个参数的改动都会对“错题集”中的图片进行测试,测试效果一目了然。
结束
通过上面的方法加上一个星期对参数的调整,我们基本实现 90% 的图片可以直出(无需人工调整)。
预告
后续,我们还需要实现将原来的文字翻译成目标语言并贴回图片中,这里我们会遇到文字颜色提取的难题,下篇文章来分享这个方案。